



Intro
A transformer is a Neural Network architecture introduced in Attention Is All You Need (Vaswani et al., 2017), which relies on a multi-head attention mechanism to model dependencies between elements in a sequence.
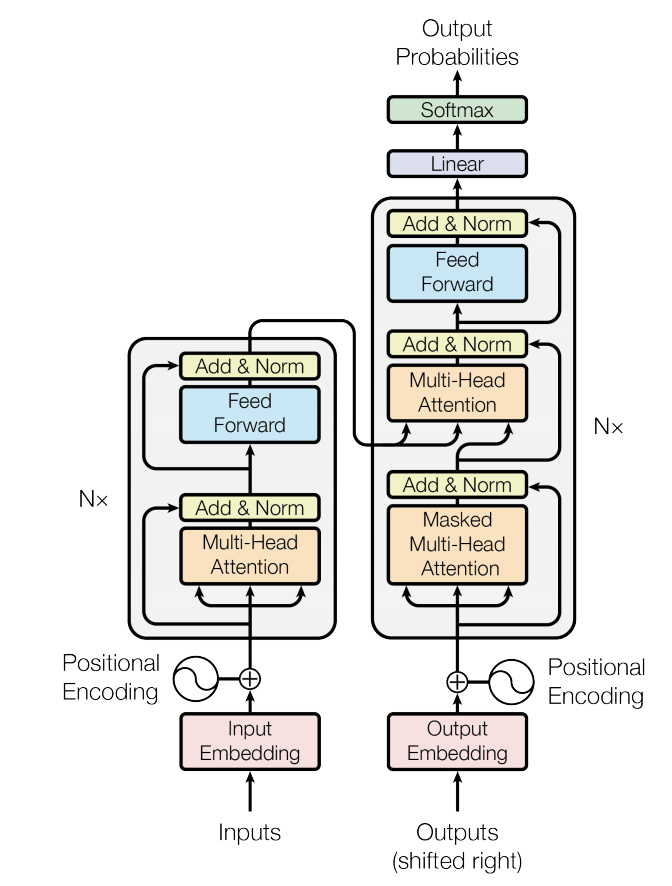
In deep learning, the transformer is an artificial neural network architecture based on the multi-head attention mechanism, in which text is converted to numerical representations called tokens, and each token is converted into a vector via lookup from a word embedding table.[1] At each layer, each token is then contextualized within the scope of the context window with other (unmasked) tokens via a parallel multi-head attention mechanism, allowing the signal for key tokens to be amplified and less important tokens to be diminished.
Transformers have the advantage of having no recurrent units, therefore requiring less training time than earlier recurrent neural architectures (RNNs) such as long short-term memory (LSTM).[2] Later variations have been widely adopted for training large language models (LLMs) on large (language) datasets.[3]