



Intro

A large language model (LLM) is a language model trained with self-supervised machine learning on a vast amount of text, designed for natural language processing tasks, especially language generation
Intro to Large Language Models | slides
LLM Training
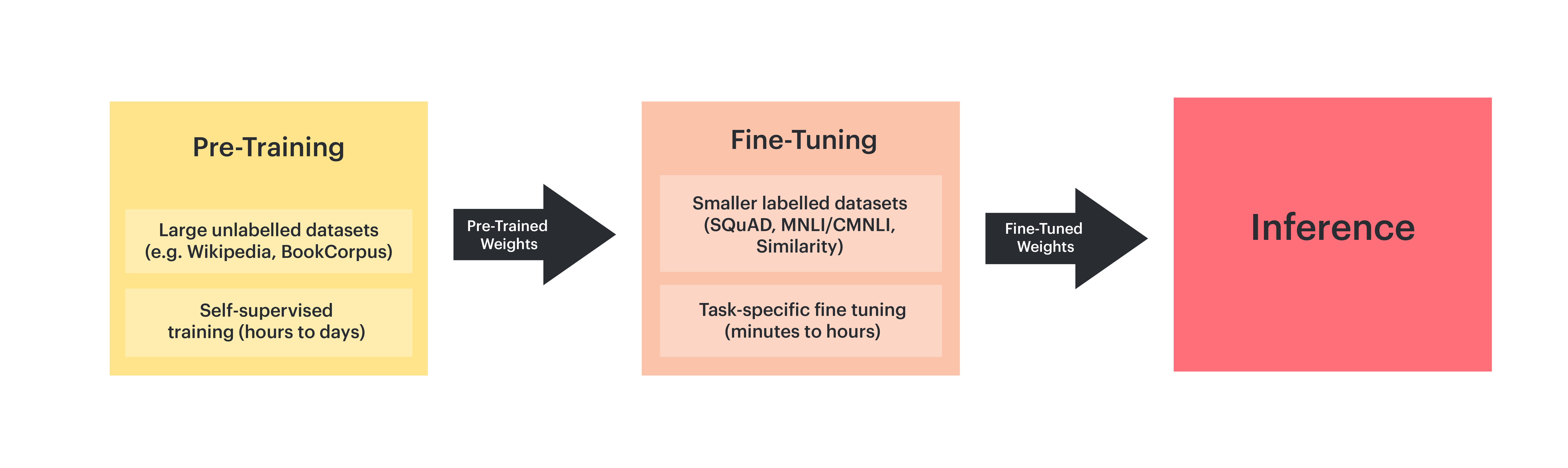
we can use these pre-trained weights as initial weights for a task-specific fine-tuning training process with a smaller amount of labelled data
Pre-training
Pre-training is the initial phase of training an LLM on a large corpus of text dataset, enabling the model to learn general language patterns, often by predicting the next token.
Fine-tuning
Fine-tuning involves training the base model on a more specific dataset to adapt it to tasks not covered during pre-training
Inference
Inference is the process of running a trained model to to generate outputs
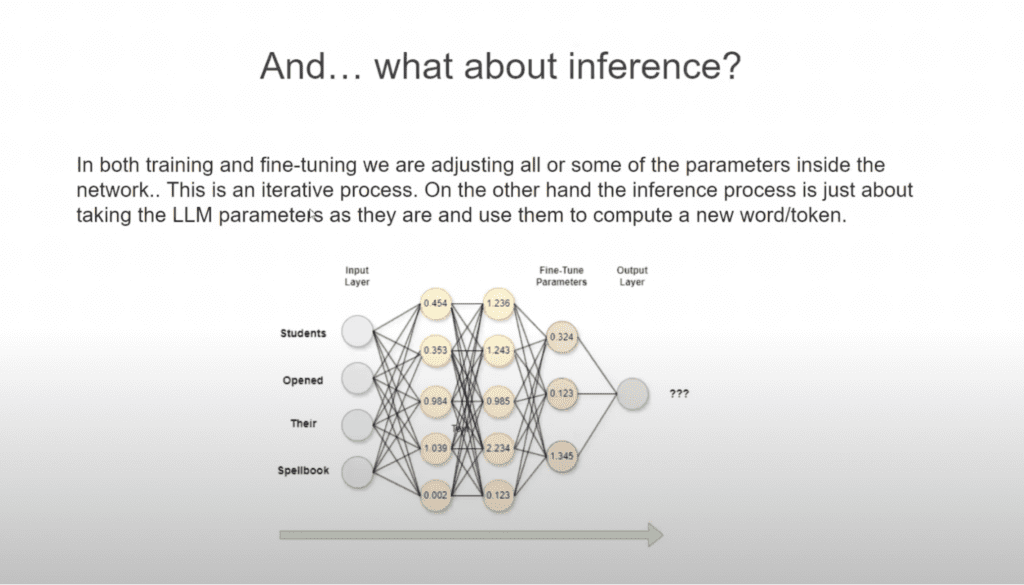
Whether it’s answering a question, generating content, or analyzing new data, inference is the phase where the AI “thinks” and produces results