



Intro
Sentence-BERT (SBERT) is a variation of BERT that is designed to generate fix-sized Embeddings for entire sentences, making it efficient for tasks like cosine similarity, semantic search, and clustering by comparing sentence vectors directly.
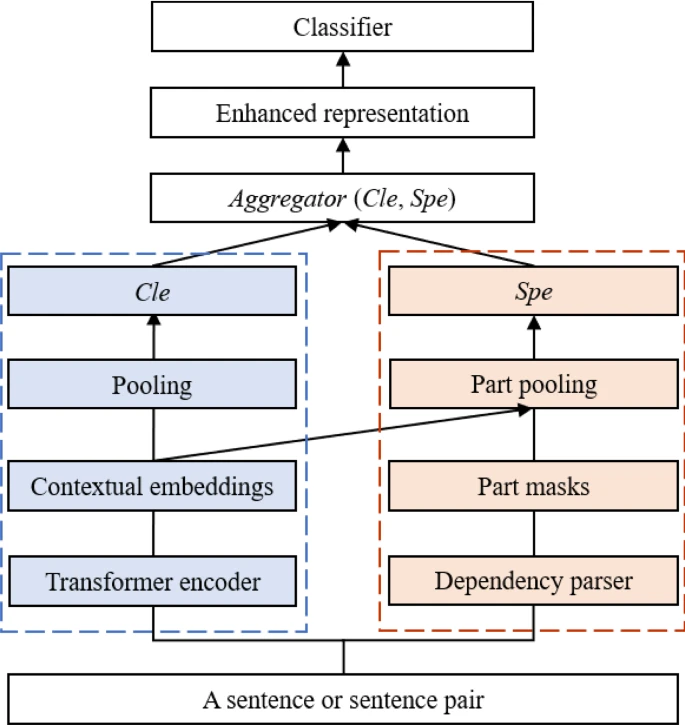
An overview of SpeBERT. The blue dotted rectangle indicates the BERT applied to learn contextual embeddings and output the embedding of the [CLS] token. The red dotted rectangle indicates the component that is applied to extract the embedding of sentence parts. The sentence representations enriched by sentence parts are utilized for the downstream tasks
Popular models:
multi-qa-MiniLM-L6-cos-v1- Small, fast (384 dim) — Good for teachingall-MiniLM-L6-v2- General purpose (384 dim)all-mpnet-base-v2- High quality (768 dim)
> So I have been using two sentence transformers, the 'sentence-transformers/all-MiniLM-L12-v2' and 'sentence-transformers/all-mpnet-base-v2'. I thought they were both working well and I could use any of them for a good document retrieval result. But I have tried their hosted inference apis and the results were pretty disappointing.
I mean, shouldn’t the sentence “The person is not happy” be the least similar one?
Is there any other model I could use that will give me better results? mpnet-base had better results but I am still not satisfied. “I ended up using
all-mpnet-base-v2”