Intro
A floating-point number is a computer representation of real numbers in binary. Floats typically use 32 bits and are stored in a form of binary scientific notation (sign, significand (mantissa), and exponent—encoded in binary). It allows for representing a very large range of values, but with limited precision, often leading to, for example, rounding errors.
Representation
- Precision:
- single precision (32-bit, ~6-7 decimal digits)
- double precision (64-bit, ~16-17 decimal digits)
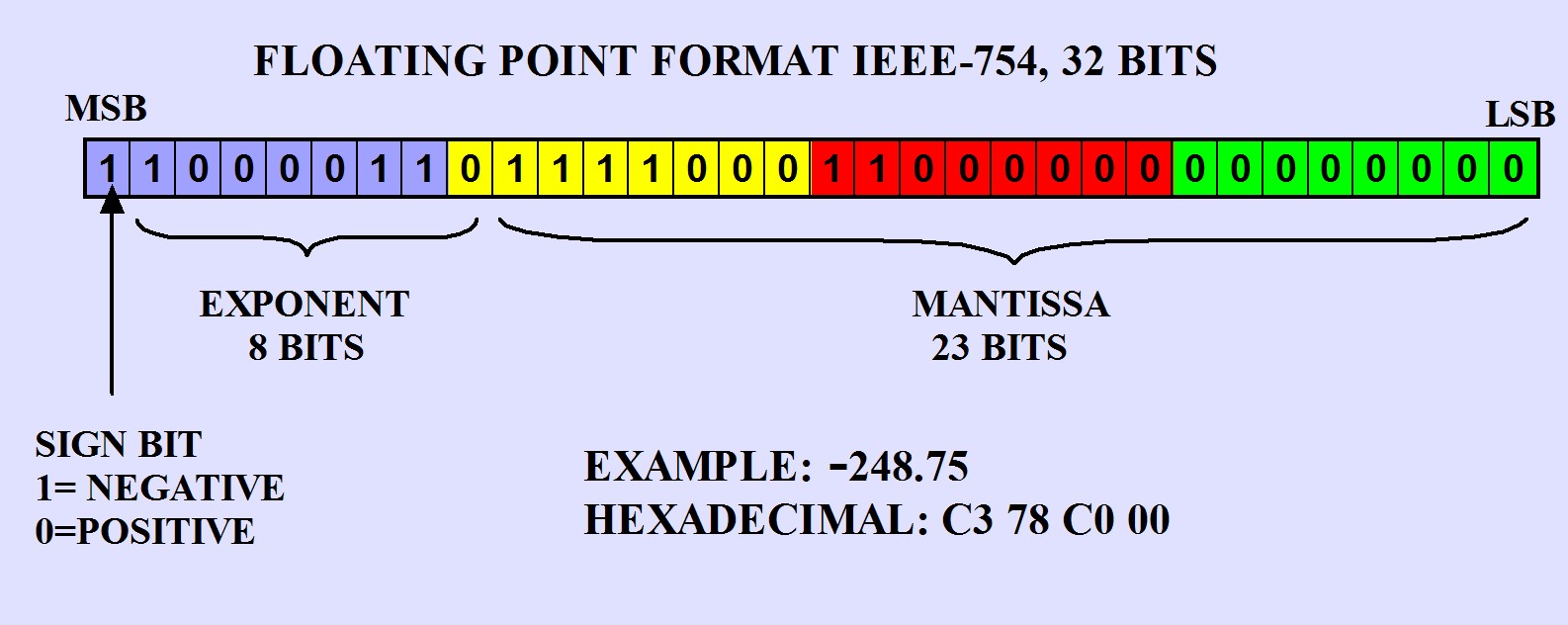
- Structure (IEEE 754 single precision):”
- sign (1 bit)
- fraction/Mantissa (23 bits)- Stores the significant digits of the number (precision).
- exponent (8 bits)- scales mantissa by a power of 2
Precision and Rounding
- Rounding Error: Not all decimal numbers can be represented exactly in binary, so floating-point arithmetic can introduce small errors.
- Example: 0.1 = 1/10 → in binary, this is a repeating fraction:
0.1 (decimal) = 0.00011001100110011… (binary, repeating)
- Overflow / underflow: Very large numbers exceed the max representable value; very small numbers fall below the min positive value and may become zero