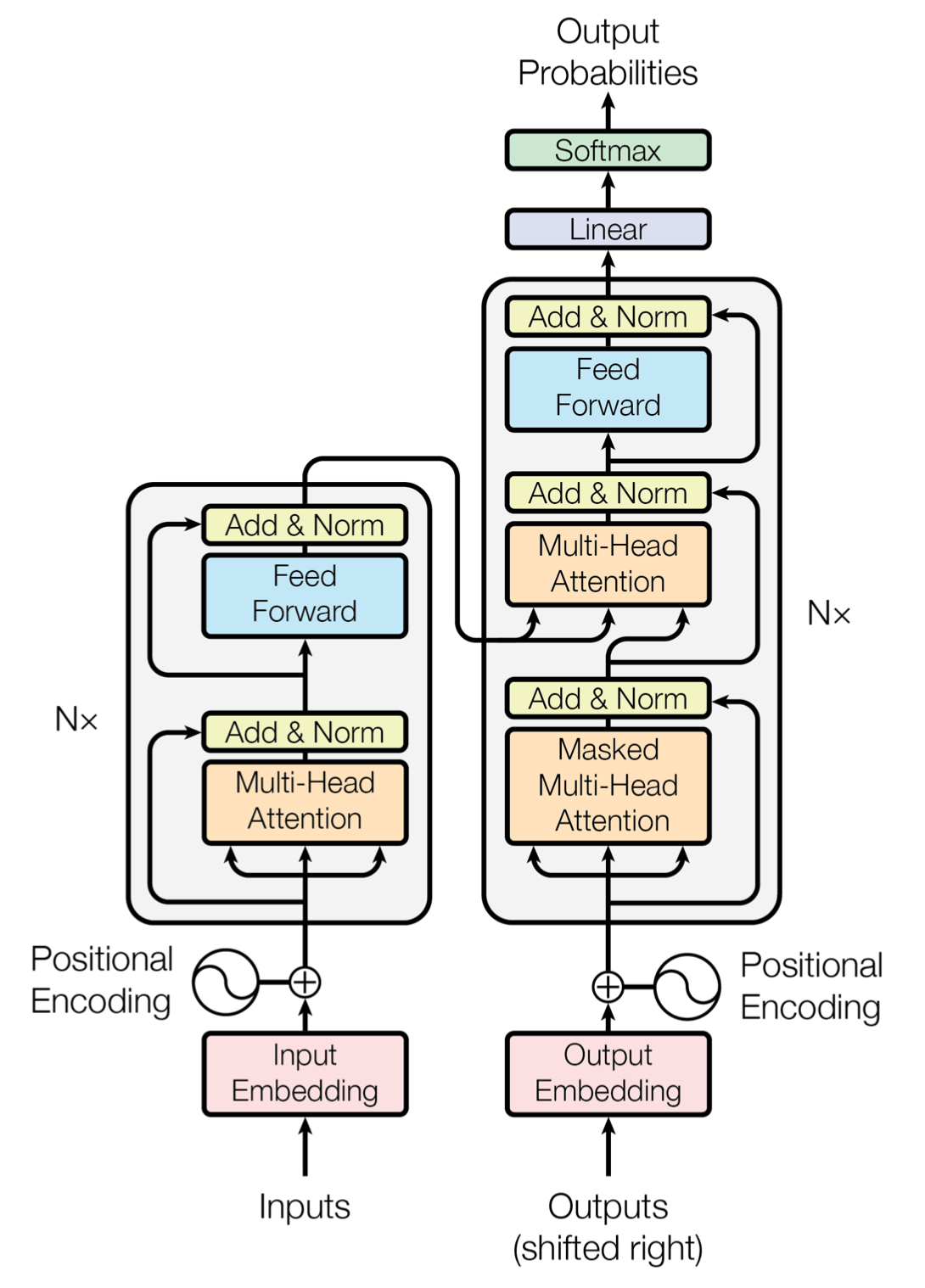
Intro
Resources
NLP
Natural Language Processing (NLP) is a field of Artificial Intelligence which focuses on enabling computers to understand, interpret, and generate human language
Modern Deep Learning Libraries
MLH Global Hack Week: Introduction to NLP
MLH Global Hack Week: Introduction to NLP

One Hot Encoding
Definition: One-hot encoding is a method of converting categorical variables into machine-readable, numerical format where each category is represented by a unique binary vector. Each vector is the same length as the number of categories, and only one element is 1 (hot), while all other elements are 0 (cold).
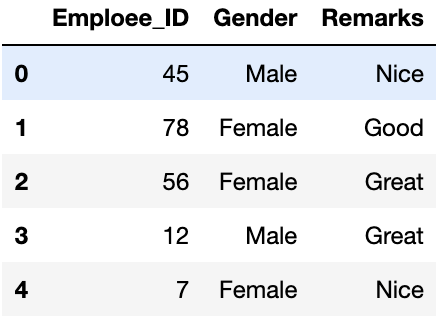
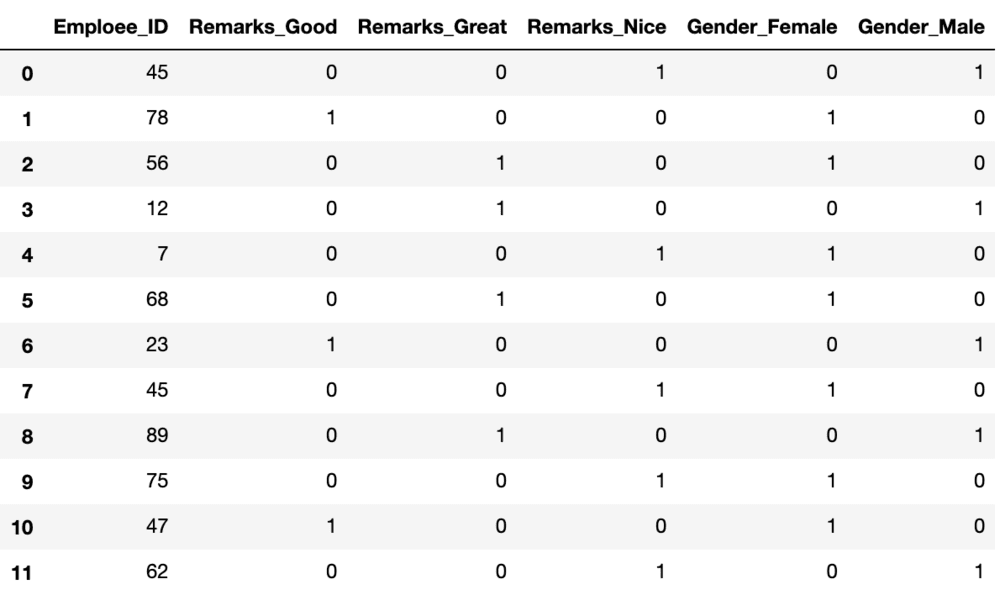
How It Works:
- Suppose you have a vocabulary of 4 words:
["cat", "dog", "fish", "bird"]. - Each word is assigned a unique index.
- The word “cat” would be represented as
[1, 0, 0, 0]. - The word “dog” would be represented as
[0, 1, 0, 0], and so on.
Characteristics:
- Simplicity: Very simple and easy to understand.
- Sparsity: The vectors are sparse, with most elements being zero.
- Dimensionality: The dimensionality of the representation is equal to the number of unique categories (vocabulary size).
- No Context: Does not capture any information about the relationships or context between categories.
One Hot Encoding using Sci-kit Learn Library:
from sklearn.preprocessing import OneHotEncoder
import numpy as np
encoder = OneHotEncoder(sparse=False)
data = np.array(["cat", "dog", "fish", "bird"]).reshape(-1, 1)
encoded = encoder.fit_transform(data)
print(encoded)Multi-hot encoding
-
Suppose we have a particular document.
- The simple one-hot or multi-hot way of dealing with this is to set one in each position in a V vocabulary length vector for every word in the document.

- The simple one-hot or multi-hot way of dealing with this is to set one in each position in a V vocabulary length vector for every word in the document.
-
Other explanations
Bag-of-Words (BoW)
Bag-of-Words is a technique for representing text data where each document or piece of text is represented by a vector of word counts or frequencies, ignoring grammar and word order but keeping track of word occurrences.
How It Works:
- Create a vocabulary of all unique words in the dataset.
- Represent each document as a vector where each element counts the occurrences of a word from the vocabulary in the document.
Characteristics:
- Frequency Information: Captures how often words appear, which can provide some insight into the content of the document.
- Sparsity: Typically results in sparse vectors, especially in large vocabularies.
- Dimensionality: The dimensionality of the representation is equal to the size of the vocabulary.
- No Context: Like one-hot encoding, it does not capture context or relationships between words.
Bag of Words using Sci-kit Learn Library:
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'cat cat dog',
'dog dog fish',
'fish bird cat'
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names_out())
print(X.toarray())Embeddings

- Context Similarity
- “I hate not eating tacos” is not the same as “I hate eating tacos”

Word2Vec

Encoder-Decorder
https://www.practicalai.io/understanding-transformer-model-architectures/
https://d2l.ai/chapter_recurrent-modern/encoder-decoder.html